

- サイトトップ
- データ自動抽出基盤 活文 Intelligent Data Extractor
AIを活用し、
システム登録作業を支援
データの取り込み、仕分け、抽出までの作業自動化を支援するデータ自動抽出基盤

- *
- 活文は、株式会社日立ソリューションズの登録商標です。
人手で行っていた入力作業やOCRの
読取位置定義の作業負荷軽減、
システム登録・確認作業の効率向上を支援します。
このような課題でお悩みではありませんか?
- 紙書類からのデータ抽出を自動化したい
- OCRを導入した際、書類の様式(項目や位置)が異なるケースで位置定義に手間がかかる
- 読み取りデータの訂正に手間がかかる
データ自動抽出基盤 活文 Intelligent Data Extractorが選ばれる理由
データ自動抽出基盤 活文 Intelligent Data Extractorは、スキャンした書類データに含まれるテキストを解析し、データを自動抽出します。抽出結果をAIが自動学習し、次回以降は学習内容をもとにデータ抽出が行われるため、抽出精度が向上します。
-
01
データの自動抽出
- 作業者は、スキャンした書類データをフォルダに格納するだけで、システムがテキストデータを自動で抽出
- 書類格納と確認作業だけの簡単運用で人手による仕分けの手間を大幅に軽減

-
02
フォーマットに依存しない設定
- 項目名とデータの位置関係を意識し、フォーマットに依存せずに設定することが可能
- 多種多様なフォーマット書類にも柔軟に対応可能

-
03
AIにより抽出間違い時の訂正学習
- 抽出データの内容が誤っていた場合は、作業者がワンクリックで簡単に訂正可能
- 訂正内容を登録することでAIが正しい情報を学習し、繰り返し学習することで抽出精度が向上

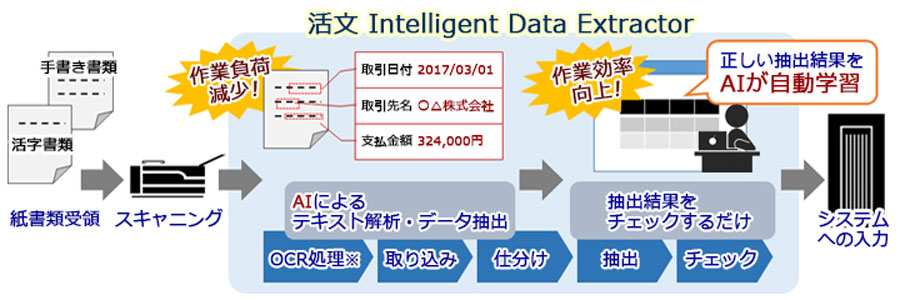
活文 Intelligent Data Extractorの概要
データ自動抽出基盤 活文 Intelligent Data Extractorは、紙書類などスキャンニングデータ(OCR処理含む)を取り込み、仕分けまで行います。AIによるテキスト分析・データ抽出を実施し、作業負荷を減少します。また、作業員は抽出結果をチェックするだけで、正しい抽出結果をAIが自動学習するため作業効率向上もはかれます。
- *
- オプション商品が必要となります。
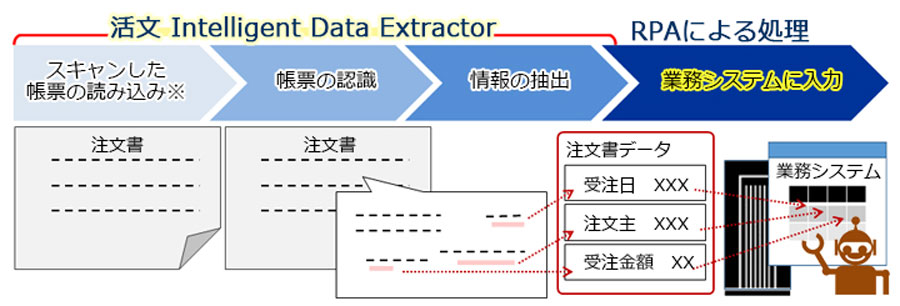
RPAとの連携で総務・調達部門などによる発注処理業務の効率化!

取引先から受領した注文書に記載された注文主、注文日などの情報や明細情報を活文がデータ抽出します。
抽出結果はRPAを活用し、発注システムへ登録します。
RPAと連携し、帳票の読み込みから業務システムへのデータ入力までの広範囲な自動化を実現します。
- *
- オプション商品が必要となります。
活文 Intelligent Data Extractorの特長
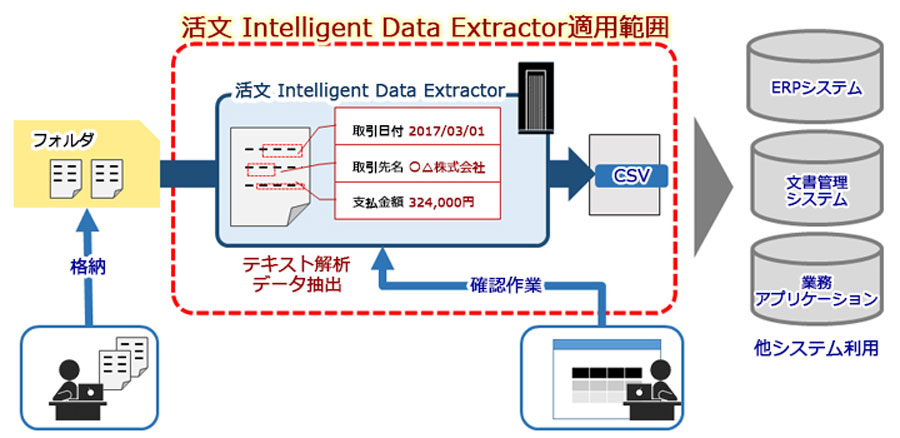
スキャンした書類データに含まれるテキストを解析し、データをCSV形式で自動抽出します。抽出結果をAIが自動学習し、次回以降は学習内容をもとにデータ抽出が行われるため、抽出精度が向上します。人手で行っていた入力作業やOCRの読取位置定義の作業負荷軽減などシステム登録・確認作業の効率化により、データエントリ業務の作業負荷を大幅に軽減できます。
自動運用
スキャンした書類のPDFデータをフォルダに格納するだけで、書類の種別ごとに自動で仕分けし、テキスト解析・データを抽出を自動でおこないます。複数ページにわたる書類も自動判別し、ページ単位で抽出結果を確認できます。
CSV出力でERPシステム・文書管理システム・業務アプリケーションなどの他システムとの連携も可能です。
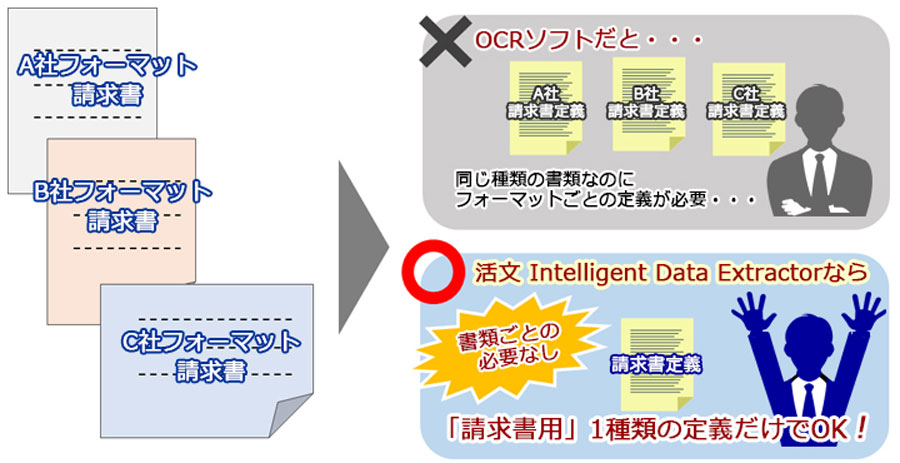
フォーマットに依存しない設定
会社ごとにフォーマットが複数ある書類でも、抽出定義は一つで大丈夫です。項目名とデータとの位置関係を意識したフォーマットに依存しない設定方法を使用していますので、多種多様なフォーマットの書類にも柔軟に対応可能です。
OCRの読取位置定義にかかっていた作業負荷を軽減します。
AIの学習機能
抽出内容が間違っていた場合も、作業者がワンクリックで訂正・登録をすることで、AIが学習します。AIが学習することで抽出精度が向上していきます。
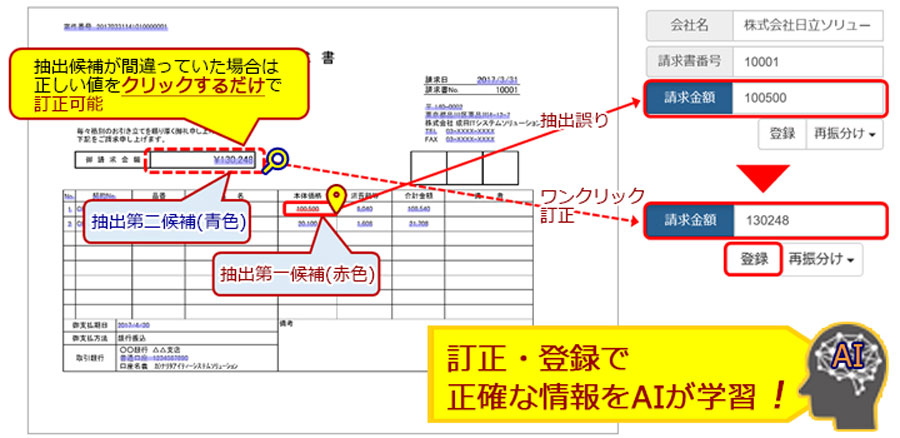
活文 Intelligent Data Extractorの適用例
請求書チェック業務効率化し、人的負荷・コストを大幅低減!
月に約数万枚発生する請求書と伝票を1枚1枚突き合わせや確認作業には人的負荷・コストがかかります。
請求書は会社ごとに異なるフォーマットのため、大量処理によるミスが生じる恐れもあります。
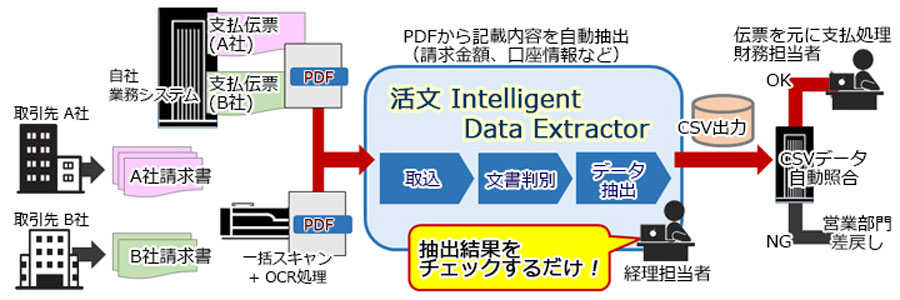
お取引先各社から送付される紙の請求書や自社業務システム伝票をスキャナ+OCRでPDF化し、活文 Intelligent Data Extractorで請求書/支払伝票の一括取込、仕分け、情報抽出を自動化することで、請求書と支払伝票の突き合わせ確認作業が削減し、人的負荷・コストを大幅低減がはかれます。
CSV出力された結果を自動照合し、財務担当者は伝票をもとに支払処理が行えます。エラーデータは営業部門へ差し戻します。
会社ごとに異なるフォーマットでもAIが学習しながら抽出するため、人為的ミス削減と処理高速化に貢献します。
RPA(Robotic Process Automation)との連携!
RPAと連携し、帳票の読み込みから業務システムへのデータ入力までの広範囲な自動化を実現します。
- *
- オプション商品が必要となります。
| 部門 | 適用可能なユースケース(例) |
|---|---|
| 営業事務 | 注文書⇒受注手配処理 |
| 調達 | 請求書の支払い処理 |
| 経理 | 振替伝票、出金伝票、入金伝票⇒経理処理 |
既存システムとの連携が可能
抽出した項目とデータをボタン1つでCSV出力し、他システムに渡して活用できます。
データ抽出部分を業務システムに組み込むためのAPIもございます。
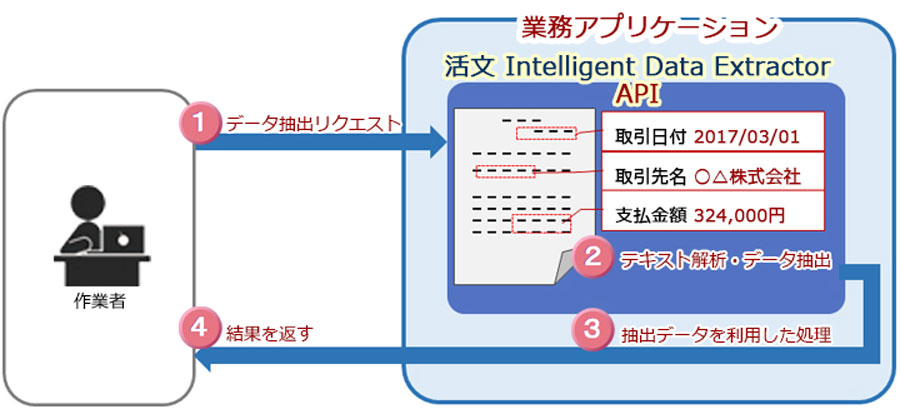
データ抽出部分を業務システムに組み込むためのAPIを使用することで、下記手順で実施できます。
- 作業員によるデータ抽出リクエスト
- API側にてテキスト解析・データ抽出
- API側にて抽出データを利用した処理実施
- 作業者へ結果を返す
関連リンク
詳細情報は、下記のサイトでも確認いただけます。
業務効率化のために、成長するAI-OCR 活文 Intelligent Data Extractor|活文|日立ソリューションズ(新規ウィンドウを表示)活文シリーズ関連商品
-
ビジネスデータ活用ソリューション
活文シリーズ文書、図面データ、帳票、画像、動画など、ビジネスの中で生まれるさまざまなコンテンツを自在に活かし、グローバル化、ワークスタイル改革、そして競争力強化といったお客さまのビジネスイノベーションを力強くサポートします。
詳しくはこちら
-
ファイルサーバースリム化
活文 File Server Optimizer企業内に増え続けるコンテンツの属性情報の収集や可視化ができます。
ファイルサーバーのリプレースやクラウド移行前に不要なファイルを整理する事により効果的な移行が行えます。詳しくはこちら
-
文書管理システム
活文 Contents Lifecycle Manager文書の作成(更新)、閲覧履歴(検索)、廃棄、保管など、ライフサイクル全般を管理でき、効率よい社内文書共有を可能にします。
詳しくはこちら